A4: Political Bias#
In this assignment, you will be trying to calculate the average political bias and reliability of posts on Bluesky.
The code you are starting with here already does a search on a Bluesky and finds the reliability and political bias of url web addresses posted there. You will need to add loop variables to calculate these averages (see chapter 8 practice and demos).
After you get the averages to work, you wll then try your code with other search terms, and then you will answer some reflection questions.
First, we’ll do our normal Bluesky login steps.
Choose Social Media Platform: Bluesky | Reddit | Discord | Mastodon | No Coding
from atproto import Client
(optional) make a fake praw connection with the fake_praw library
For testing purposes, we’ve added this line of code, which loads a fake version of praw, so it wont actually connect to reddit. If you want to try to actually connect to reddit, don’t run this line of code.
%run ../../../../fake_apis/fake_atproto.ipynb
%run bluesky_keys.py
client = Client(base_url="https://bsky.social")
client.login(handle, password)
TODO: Fill in Bias and Reliability Info#
The first step to make this work is to fill in info for the bias and reliability of different websites.
If you open media_info.csv, you’ll see a bunch of partial website links (enough to identify which site the link is for), and then blank spots for the reliability and bias of that website news sources.
You’ll use the Media Bias chart to look up one organizations ratings of bias and reliability info for each of those sites.
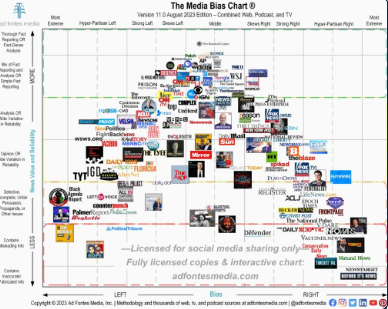
So, open that file and then for each of the sites listed, fill in a number for the bias and reliability of the site (you’ll have to figure out how you want to turn bias and reliability into numbers). You can add additional sites as well if you want.
Load Bias and Reliability Info#
The code to load the bias and reliability info is in another file: a4-supporting_code.ipynb. You can look at that file if you are interested, but you are not required to.
# You can look in this file if you want to see more
# about how the file information is loaded
%run a4-supporting_code.ipynb
Helper function for looking up urls#
Note: You don’t have to worry about the details of how this works, but the basic idea is it takes url shortener links and turns them into the actual links
# This helper function will help us look up full urls, since some posts come with shortened ones
# It has a bunch of checks to timeout on DNS connections and reads, and tries 3 times to find the URL
# If it fails, it just gives up and gives you the short url
import requests
from time import sleep
def get_full_url(short_url, timeout=(2, 5), retries=3):
for attempt in range(retries):
try:
response = requests.head(short_url, allow_redirects=True, timeout=timeout)
return response.url
except requests.Timeout:
print(f"Timeout on attempt {attempt + 1} for URL: {short_url}")
if attempt < retries - 1:
sleep(1) # Optional: wait before retrying
except requests.RequestException as e:
print(f"Error retrieving URL: {e}")
return short_url
return short_url # Return the original if all attempts fail
Get a list of search results from Bluesky#
We will now get a list of results from Bluesky. To start with, we’ll try to get 100 with the search term “Seattle.”
# The "params" variable is what we send as a search request to bluesky
# 'q' is the search query; edit this if you want to try different search terms
# 'limit' is the maximum number of posts you'll extract.
params = {
'q': "news",
'limit': 100
}
posts = client.app.bsky.feed.search_posts(params=params).posts
TODO: Modify the code below (Run Search)#
The code below loops through each bluesky post, and if the submission was a website url, the program checks to see if we have reliability/bias info on the site. If we have that info we calculate the bias and reliability and display it.
Your job is to add loop variables to the code to calculate the number of urls we had info for (number_matched_urls) and then the total bias and total reliability for those urls. Then you can use that at the end to calculate the average bias and average reliability.
#### TODO: Create your loop variables here
# Go through all the posts
for p in posts:
embed = p.record.embed
# Check if the post has an external link
if hasattr(embed, 'external'):
url = embed.external.uri
#Need to check if we can find the full url, so our lookup is more accurate
#Note
print("Checking for full url...")
full_url = get_full_url(url)
print(full_url)
# try to find the source website in our dataset
matching_site = find_matching_site(full_url)
# if we found the matching site, then we have info for it
if(matching_site):
# look up the bias and reliability for the site the url is from
url_bias = media_bias_lookup[matching_site]
url_reliability = media_reliability_lookup[matching_site]
#### TODO: Update the three loop variables here ####
print(" bias: " + str(url_bias))
print(" reliability: " + str(url_reliability))
else:
# We didn't have info on this site
print("**did not recognize site!")
print()
#### TODO: calculate the averages below and output the total and averages
# Note: It's ok if the code gives an error when no urls are found
# (since trying to find the average might cause a divide by 0 error)
print("--------------------------------------")
print("Total number of urls we could measure: ")
print("Average bias: ")
print("Average reliability: ")
Checking for full url...
http://example.com/fake_news_story
**did not recognize site!
Checking for full url...
http://example.com/pretend_news_story
**did not recognize site!
Checking for full url...
http://example.com/imaginary_news_story
**did not recognize site!
Checking for full url...
http://example.com/mysterious_news_story
**did not recognize site!
--------------------------------------
Total number of urls we could measure:
Average bias:
Average reliability:
Reflection tasks#
Once you get the code above working and finding an average bias and reliability, modify the search to try at least three different searches. Open up the bluesky separately and try the same searches look at your results, then answer the questions below.
Note: For searches, you can search try different search terms that might have different views and post links to news articles, like: “news”, “science”, “politics”, “liberal”, “conservative”, “tech”, “BlackLivesMatter”, etc.
What additional searches did you run (at least 3)?
TODO: Answer question here
When doing those searches, what were your observations about the calculations of media bias and reliability? (For example: were there a lot of urls that you didn’t measure? Do you feel like the final calculated bias and reliability match the search results?). Answer with at least 3 sentences
TODO: Answer question here
If you could redesign the Media Bias Chart, what would you want to do (e.g., add some other dimension besides just bias/responsibility, change how it is evaluated, add more news sources, consider different countries)? Answer with at least 3 sentences.
TODO: Answer question here
What might a social media companies or advertizers (including political campaigns) want to do with information on a users’ political views and susceptibility to consipracy theories? Answer with at least 3 sentences.
TODO: Answer question here
Choose two ethics frameworks and use the frameworks to consider the different uses of the media bias and reliability information. Answer with at least 6 sentences total (e.g., 3 per framework).
TODO: Answer question here